
360環視實時性評估:GPU加速性能與AI拓展潛力-基于米爾RK3576
http://www.debgrams.com 2025-11-27 14:59 來源:米爾電子
一、 項目背景與測試平臺
本次360環視系統原型基于米爾科技MYD-LR3576開發板進行構建與評估。該開發板所搭載的瑞芯微RK3576芯片,集成了4核Cortex-A72、4核Cortex-A53、Mali-G52 GPU及高達6TOPS算力的NPU。本文旨在通過實際測試數據,從功能實現、實時性能與AI拓展潛力三大核心維度,為客戶提供一份關于該平臺在360環視應用中能力的真實參考。
二、 系統流程與功能實現
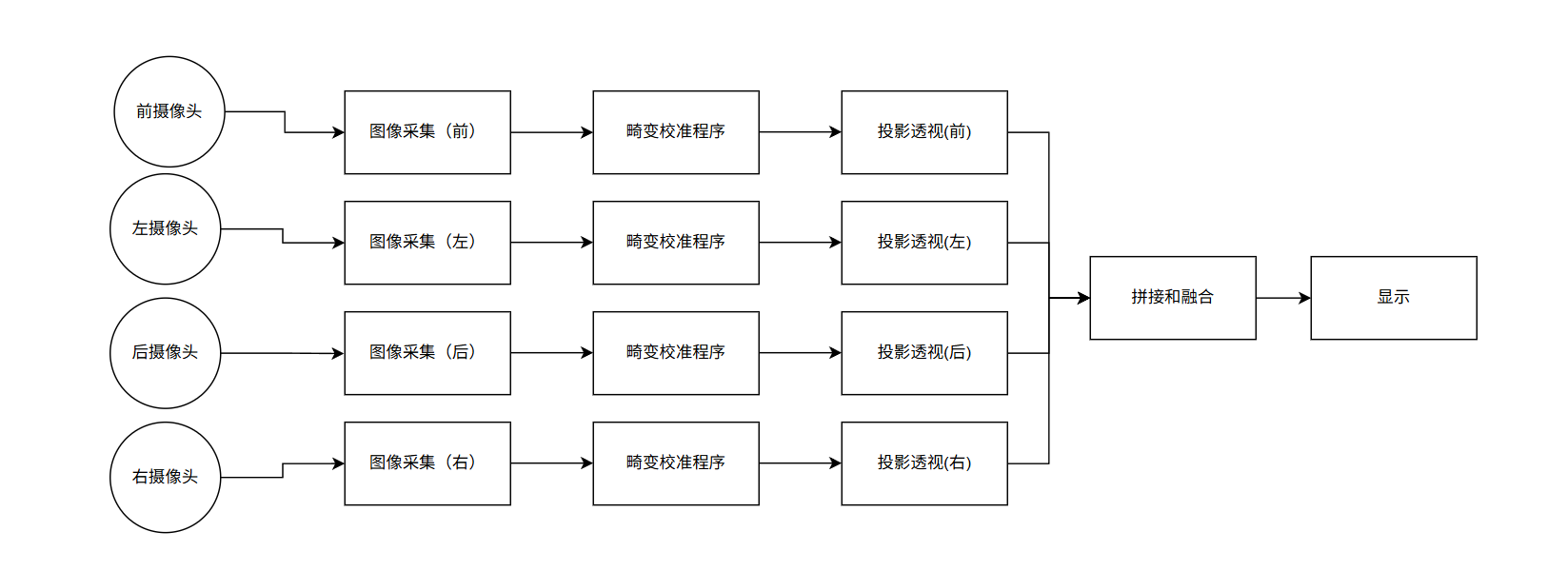
圖:程序流程圖
一套標準的360環視處理流水線已在開發板上成功實現,驗證了其功能可行性:
1.傳感器配置: 4路720P分辨率魚眼攝像頭,精確固定于模擬車輛的四周。
2.核心處理流水線:
畸變矯正: 利用張正友標定法預先獲取攝像頭內參和畸變系數,實時消除魚眼鏡頭產生的圖像扭曲。
投影變換: 通過預設的單應性矩陣(Homography Matrix),將矯正后的透視圖像轉換為統一的俯瞰視角鳥瞰圖。
圖像拼接: 依據預先標定的位置關系,將四張鳥瞰圖無縫合成為一張完整的360°全景俯視圖。
顯示: 為快速驗證核心流程,目前采用OpenCV imshow函數進行結果顯示,已知其效率非最優,后續將優化為DRM/KMS等低延遲工業級方案。
畸變矯正前:

畸變矯正后:

投影視圖:

圖像拼接效果:

360環視視頻效果演示:
三、 性能實測:CPU與GPU的算力博弈
性能是決定方案能否商用的關鍵。我們以行業通用的25fps(即每幀處理間隔40ms)作為實時性標準,在米爾MYD-LR3576開發板上對數據處理管線進行了精細的性能剖析,關鍵數據對比如下:
圖:CPU負載情況

圖:GPU負載情況
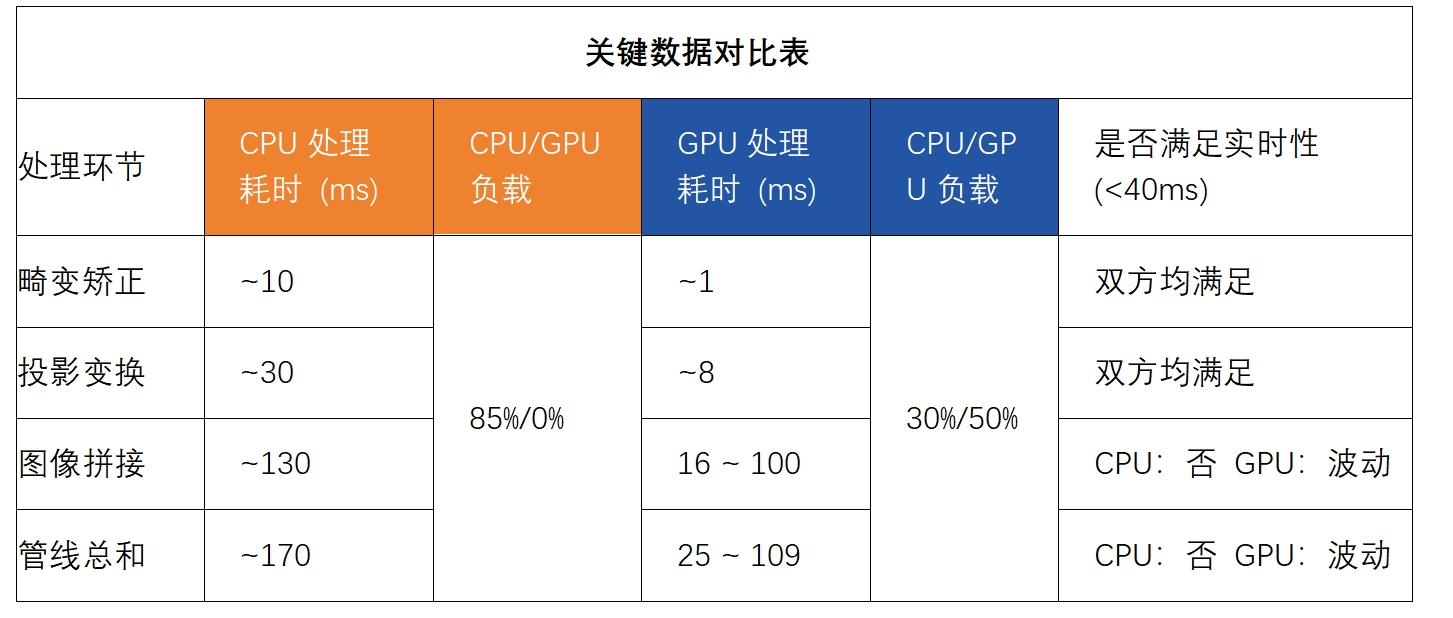
深度性能分析:
CPU方案:功能完整,但實時性無望
如上表數據所示,當所有處理任務均由CPU承擔時,總耗時高達170ms,遠超40ms的預算。其中,計算密集型的圖像拼接成為絕對的性能瓶頸,幾乎占滿了所有A72大核的資源。這不僅導致系統無法實時處理視頻流,造成嚴重卡頓和延遲,也使得CPU再無余力處理其他系統任務,此方案不具備產品化價值。
GPU方案:潛力巨大,穩定性是當前關鍵瓶頸
卓越的算力體現: 在畸變矯正和投影變換環節,Mali-G52 GPU展現了其強大的并行計算能力,耗時相比CPU降低了數倍至一個數量級,且占用率較低,證明其處理此類像素級操作的高效性。
拼接環節的性能波動: 圖像拼接的耗時在16ms到100ms之間劇烈波動,這是阻礙當前方案投入實用的核心問題。GPU占用率的相應大幅變動,暗示了問題根源。
根因推測與進展: 這種波動極有可能源于GPU內部的內存管理機制,如圖像數據在顯存中的頻繁拷貝、同步等待或驅動調度開銷。我們已將此性能波動問題作為高優先級案例提交給瑞芯微原廠技術支持。若能通過驅動或底層優化將拼接時間穩定在16ms的理想區間,則整個GPU處理管線可在25ms內完成,完全滿足一幀內的處理需求。
四、 未來拓展:釋放NPU算力,實現從“看到”到“理解”的飛躍
當GPU處理管線優化完成后,我們將獲得一個極具吸引力的系統狀態:充裕的時間預算和富余的CPU資源。這為集成更高價值的AI功能奠定了堅實基礎。
剩余時間預算分析:
在25fps幀率下,系統必須在40ms內完成一幀的所有處理。假設GPU流水線穩定在25ms完成環視基礎處理,那么系統還剩下約15ms的時間裕度。
NPU的用武之地:
這15ms的寶貴時間,正是留給RK3576內置的6TOPS NPU大顯身手的舞臺。我們可以利用這部分算力,在環視全景圖或原始魚眼圖上并行運行輕量化的AI模型,實現功能的全面升級,例如:
障礙物檢測與識別: 精準識別車輛周圍的行人、車輛、錐桶等障礙物。
空間距離估算: 基于俯視圖的幾何關系,實時計算識別出的物體與車身的精確距離。
主動預警系統: 當距離低于安全閾值時,立即觸發聲音或視覺警報,實現真正的主動安全功能。
總結與展望

圖:米爾基于RM3576開發板
功能實現: 基于米爾MYD-LR3576開發板的RK3576平臺完全具備實現高質量360環視全鏈路功能的能力。
實時性能: 純CPU方案無法滿足25fps實時需求。GPU方案擁有足夠的算力潛力,但其執行的穩定性是當前能否商用的關鍵挑戰。
方案潛力與價值: 一旦GPU性能穩定,RK3576憑借其異構計算架構(CPU+GPU+NPU),能夠在一幀時間內不僅完成環視合成,更能集成復雜的AI感知與預警功能。這使其從一個單純的環視處理器,升級為一個高集成度、高附加值的智能視覺平臺。
相關新聞
- ? 從兩輪車儀表到工程機械環視,米爾電子助力國產 HMI 顯控一體化突圍
- ? 【深度實戰】米爾RK3576開發板AMP非對稱多核開發指南:從配置到實戰
- ? 定制未來,共建生態,米爾出席安路研討會
- ? 米爾SECC方案助力國標充電樁出海
- ? 米爾RK3576邊緣計算盒精準驅動菜品識別模型性能強悍
- ? 米爾與安路聯合亮相VisionChina 2025,共推FPGA視覺方案
- ? 經典再進化:米爾ZYNQ 7010/7020全面適配2024.2工具鏈
- ? 經典再進化:米爾ZYNQ 7010/7020全面適配2024.2工具鏈
- ? 從微秒級響應到確定性延遲:深入解析米爾全志T536核心板的實時性技術突破
- ? 米爾電子獲全志科技生態認證,共推工業智能化升級
編輯精選


